🔎 Logging - Custom Callbacks, Langfuse, ClickHouse, s3 Bucket, Sentry, OpenTelemetry, Athina
Log Proxy Input, Output, Exceptions using Custom Callbacks, Langfuse, OpenTelemetry, LangFuse, DynamoDB, s3 Bucket
- Async Custom Callbacks
- Async Custom Callback APIs
- Logging to ClickHouse
- Logging to Langfuse
- Logging to s3 Buckets
- Logging to DynamoDB
- Logging to Sentry
- Logging to Traceloop (OpenTelemetry)
- Logging to Athina
Custom Callback Class [Async]
Use this when you want to run custom callbacks in python
Step 1 - Create your custom litellm callback class
We use litellm.integrations.custom_logger for this, more details about litellm custom callbacks here
Define your custom callback class in a python file.
Here's an example custom logger for tracking key, user, model, prompt, response, tokens, cost. We create a file called custom_callbacks.py and initialize proxy_handler_instance
from litellm.integrations.custom_logger import CustomLogger
import litellm
# This file includes the custom callbacks for LiteLLM Proxy
# Once defined, these can be passed in proxy_config.yaml
class MyCustomHandler(CustomLogger):
def log_pre_api_call(self, model, messages, kwargs):
print(f"Pre-API Call")
def log_post_api_call(self, kwargs, response_obj, start_time, end_time):
print(f"Post-API Call")
def log_stream_event(self, kwargs, response_obj, start_time, end_time):
print(f"On Stream")
def log_success_event(self, kwargs, response_obj, start_time, end_time):
print("On Success")
def log_failure_event(self, kwargs, response_obj, start_time, end_time):
print(f"On Failure")
async def async_log_success_event(self, kwargs, response_obj, start_time, end_time):
print(f"On Async Success!")
# log: key, user, model, prompt, response, tokens, cost
# Access kwargs passed to litellm.completion()
model = kwargs.get("model", None)
messages = kwargs.get("messages", None)
user = kwargs.get("user", None)
# Access litellm_params passed to litellm.completion(), example access `metadata`
litellm_params = kwargs.get("litellm_params", {})
metadata = litellm_params.get("metadata", {}) # headers passed to LiteLLM proxy, can be found here
# Calculate cost using litellm.completion_cost()
cost = litellm.completion_cost(completion_response=response_obj)
response = response_obj
# tokens used in response
usage = response_obj["usage"]
print(
f"""
Model: {model},
Messages: {messages},
User: {user},
Usage: {usage},
Cost: {cost},
Response: {response}
Proxy Metadata: {metadata}
"""
)
return
async def async_log_failure_event(self, kwargs, response_obj, start_time, end_time):
try:
print(f"On Async Failure !")
print("\nkwargs", kwargs)
# Access kwargs passed to litellm.completion()
model = kwargs.get("model", None)
messages = kwargs.get("messages", None)
user = kwargs.get("user", None)
# Access litellm_params passed to litellm.completion(), example access `metadata`
litellm_params = kwargs.get("litellm_params", {})
metadata = litellm_params.get("metadata", {}) # headers passed to LiteLLM proxy, can be found here
# Acess Exceptions & Traceback
exception_event = kwargs.get("exception", None)
traceback_event = kwargs.get("traceback_exception", None)
# Calculate cost using litellm.completion_cost()
cost = litellm.completion_cost(completion_response=response_obj)
print("now checking response obj")
print(
f"""
Model: {model},
Messages: {messages},
User: {user},
Cost: {cost},
Response: {response_obj}
Proxy Metadata: {metadata}
Exception: {exception_event}
Traceback: {traceback_event}
"""
)
except Exception as e:
print(f"Exception: {e}")
proxy_handler_instance = MyCustomHandler()
# Set litellm.callbacks = [proxy_handler_instance] on the proxy
# need to set litellm.callbacks = [proxy_handler_instance] # on the proxy
Step 2 - Pass your custom callback class in config.yaml
We pass the custom callback class defined in Step1 to the config.yaml.
Set callbacks to python_filename.logger_instance_name
In the config below, we pass
- python_filename:
custom_callbacks.py - logger_instance_name:
proxy_handler_instance. This is defined in Step 1
callbacks: custom_callbacks.proxy_handler_instance
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
callbacks: custom_callbacks.proxy_handler_instance # sets litellm.callbacks = [proxy_handler_instance]
Step 3 - Start proxy + test request
litellm --config proxy_config.yaml
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Authorization: Bearer sk-1234' \
--data ' {
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "good morning good sir"
}
],
"user": "ishaan-app",
"temperature": 0.2
}'
Resulting Log on Proxy
On Success
Model: gpt-3.5-turbo,
Messages: [{'role': 'user', 'content': 'good morning good sir'}],
User: ishaan-app,
Usage: {'completion_tokens': 10, 'prompt_tokens': 11, 'total_tokens': 21},
Cost: 3.65e-05,
Response: {'id': 'chatcmpl-8S8avKJ1aVBg941y5xzGMSKrYCMvN', 'choices': [{'finish_reason': 'stop', 'index': 0, 'message': {'content': 'Good morning! How can I assist you today?', 'role': 'assistant'}}], 'created': 1701716913, 'model': 'gpt-3.5-turbo-0613', 'object': 'chat.completion', 'system_fingerprint': None, 'usage': {'completion_tokens': 10, 'prompt_tokens': 11, 'total_tokens': 21}}
Proxy Metadata: {'user_api_key': None, 'headers': Headers({'host': '0.0.0.0:4000', 'user-agent': 'curl/7.88.1', 'accept': '*/*', 'authorization': 'Bearer sk-1234', 'content-length': '199', 'content-type': 'application/x-www-form-urlencoded'}), 'model_group': 'gpt-3.5-turbo', 'deployment': 'gpt-3.5-turbo-ModelID-gpt-3.5-turbo'}
Logging Proxy Request Object, Header, Url
Here's how you can access the url, headers, request body sent to the proxy for each request
class MyCustomHandler(CustomLogger):
async def async_log_success_event(self, kwargs, response_obj, start_time, end_time):
print(f"On Async Success!")
litellm_params = kwargs.get("litellm_params", None)
proxy_server_request = litellm_params.get("proxy_server_request")
print(proxy_server_request)
Expected Output
{
"url": "http://testserver/chat/completions",
"method": "POST",
"headers": {
"host": "testserver",
"accept": "*/*",
"accept-encoding": "gzip, deflate",
"connection": "keep-alive",
"user-agent": "testclient",
"authorization": "Bearer None",
"content-length": "105",
"content-type": "application/json"
},
"body": {
"model": "Azure OpenAI GPT-4 Canada",
"messages": [
{
"role": "user",
"content": "hi"
}
],
"max_tokens": 10
}
}
Logging model_info set in config.yaml
Here is how to log the model_info set in your proxy config.yaml. Information on setting model_info on config.yaml
class MyCustomHandler(CustomLogger):
async def async_log_success_event(self, kwargs, response_obj, start_time, end_time):
print(f"On Async Success!")
litellm_params = kwargs.get("litellm_params", None)
model_info = litellm_params.get("model_info")
print(model_info)
Expected Output
{'mode': 'embedding', 'input_cost_per_token': 0.002}
Logging responses from proxy
Both /chat/completions and /embeddings responses are available as response_obj
Note: for /chat/completions, both stream=True and non stream responses are available as response_obj
class MyCustomHandler(CustomLogger):
async def async_log_success_event(self, kwargs, response_obj, start_time, end_time):
print(f"On Async Success!")
print(response_obj)
Expected Output /chat/completion [for both stream and non-stream responses]
ModelResponse(
id='chatcmpl-8Tfu8GoMElwOZuj2JlHBhNHG01PPo',
choices=[
Choices(
finish_reason='stop',
index=0,
message=Message(
content='As an AI language model, I do not have a physical body and therefore do not possess any degree or educational qualifications. My knowledge and abilities come from the programming and algorithms that have been developed by my creators.',
role='assistant'
)
)
],
created=1702083284,
model='chatgpt-v-2',
object='chat.completion',
system_fingerprint=None,
usage=Usage(
completion_tokens=42,
prompt_tokens=5,
total_tokens=47
)
)
Expected Output /embeddings
{
'model': 'ada',
'data': [
{
'embedding': [
-0.035126980394124985, -0.020624293014407158, -0.015343423001468182,
-0.03980357199907303, -0.02750781551003456, 0.02111034281551838,
-0.022069307044148445, -0.019442008808255196, -0.00955679826438427,
-0.013143060728907585, 0.029583381488919258, -0.004725852981209755,
-0.015198921784758568, -0.014069183729588985, 0.00897879246622324,
0.01521205808967352,
# ... (truncated for brevity)
]
}
]
}
Custom Callback APIs [Async]
This is an Enterprise only feature Get Started with Enterprise here
Use this if you:
- Want to use custom callbacks written in a non Python programming language
- Want your callbacks to run on a different microservice
Step 1. Create your generic logging API endpoint
Set up a generic API endpoint that can receive data in JSON format. The data will be included within a "data" field.
Your server should support the following Request format:
curl --location https://your-domain.com/log-event \
--request POST \
--header "Content-Type: application/json" \
--data '{
"data": {
"id": "chatcmpl-8sgE89cEQ4q9biRtxMvDfQU1O82PT",
"call_type": "acompletion",
"cache_hit": "None",
"startTime": "2024-02-15 16:18:44.336280",
"endTime": "2024-02-15 16:18:45.045539",
"model": "gpt-3.5-turbo",
"user": "ishaan-2",
"modelParameters": "{'temperature': 0.7, 'max_tokens': 10, 'user': 'ishaan-2', 'extra_body': {}}",
"messages": "[{'role': 'user', 'content': 'This is a test'}]",
"response": "ModelResponse(id='chatcmpl-8sgE89cEQ4q9biRtxMvDfQU1O82PT', choices=[Choices(finish_reason='length', index=0, message=Message(content='Great! How can I assist you with this test', role='assistant'))], created=1708042724, model='gpt-3.5-turbo-0613', object='chat.completion', system_fingerprint=None, usage=Usage(completion_tokens=10, prompt_tokens=11, total_tokens=21))",
"usage": "Usage(completion_tokens=10, prompt_tokens=11, total_tokens=21)",
"metadata": "{}",
"cost": "3.65e-05"
}
}'
Reference FastAPI Python Server
Here's a reference FastAPI Server that is compatible with LiteLLM Proxy:
# this is an example endpoint to receive data from litellm
from fastapi import FastAPI, HTTPException, Request
app = FastAPI()
@app.post("/log-event")
async def log_event(request: Request):
try:
print("Received /log-event request")
# Assuming the incoming request has JSON data
data = await request.json()
print("Received request data:")
print(data)
# Your additional logic can go here
# For now, just printing the received data
return {"message": "Request received successfully"}
except Exception as e:
print(f"Error processing request: {str(e)}")
import traceback
traceback.print_exc()
raise HTTPException(status_code=500, detail="Internal Server Error")
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="127.0.0.1", port=4000)
Step 2. Set your GENERIC_LOGGER_ENDPOINT to the endpoint + route we should send callback logs to
os.environ["GENERIC_LOGGER_ENDPOINT"] = "http://localhost:4000/log-event"
Step 3. Create a config.yaml file and set litellm_settings: success_callback = ["generic"]
Example litellm proxy config.yaml
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
success_callback: ["generic"]
Start the LiteLLM Proxy and make a test request to verify the logs reached your callback API
Logging Proxy Input/Output - Langfuse
We will use the --config to set litellm.success_callback = ["langfuse"] this will log all successfull LLM calls to langfuse
Step 1 Install langfuse
pip install langfuse>=2.0.0
Step 2: Create a config.yaml file and set litellm_settings: success_callback
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
success_callback: ["langfuse"]
Step 3: Start the proxy, make a test request
Start proxy
litellm --config config.yaml --debug
Test Request
litellm --test
Expected output on Langfuse
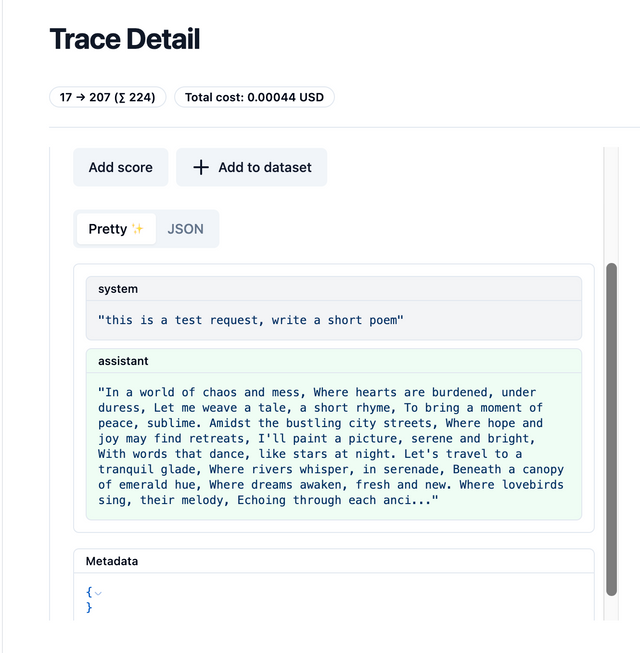
Logging Metadata to Langfuse
- Curl Request
- OpenAI v1.0.0+
- Langchain
Pass metadata as part of the request body
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data '{
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
],
"metadata": {
"generation_name": "ishaan-test-generation",
"generation_id": "gen-id22",
"trace_id": "trace-id22",
"trace_user_id": "user-id2"
}
}'
Set extra_body={"metadata": { }} to metadata you want to pass
import openai
client = openai.OpenAI(
api_key="anything",
base_url="http://0.0.0.0:4000"
)
# request sent to model set on litellm proxy, `litellm --model`
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages = [
{
"role": "user",
"content": "this is a test request, write a short poem"
}
],
extra_body={
"metadata": {
"generation_name": "ishaan-generation-openai-client",
"generation_id": "openai-client-gen-id22",
"trace_id": "openai-client-trace-id22",
"trace_user_id": "openai-client-user-id2"
}
}
)
print(response)
from langchain.chat_models import ChatOpenAI
from langchain.prompts.chat import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
SystemMessagePromptTemplate,
)
from langchain.schema import HumanMessage, SystemMessage
chat = ChatOpenAI(
openai_api_base="http://0.0.0.0:4000",
model = "gpt-3.5-turbo",
temperature=0.1,
extra_body={
"metadata": {
"generation_name": "ishaan-generation-langchain-client",
"generation_id": "langchain-client-gen-id22",
"trace_id": "langchain-client-trace-id22",
"trace_user_id": "langchain-client-user-id2"
}
}
)
messages = [
SystemMessage(
content="You are a helpful assistant that im using to make a test request to."
),
HumanMessage(
content="test from litellm. tell me why it's amazing in 1 sentence"
),
]
response = chat(messages)
print(response)
Logging Proxy Input/Output - Clickhouse
We will use the --config to set litellm.success_callback = ["clickhouse"] this will log all successfull LLM calls to ClickHouse DB
[Optional] - Docker Compose - LiteLLM Proxy + Self Hosted Clickhouse DB
Use this docker compose yaml to start LiteLLM Proxy + Clickhouse DB
version: "3.9"
services:
litellm:
image: ghcr.io/berriai/litellm:main-latest
volumes:
- ./proxy_server_config.yaml:/app/proxy_server_config.yaml # mount your litellm config.yaml
ports:
- "4000:4000"
environment:
- AZURE_API_KEY=sk-123
clickhouse:
image: clickhouse/clickhouse-server
environment:
- CLICKHOUSE_DB=litellm-test
- CLICKHOUSE_USER=admin
- CLICKHOUSE_DEFAULT_ACCESS_MANAGEMENT=1
- CLICKHOUSE_PASSWORD=admin
ports:
- "8123:8123"
Step 1: Create a config.yaml file and set litellm_settings: success_callback
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
success_callback: ["clickhouse"]
Step 2: Set Required env variables for clickhouse
- Self Hosted Clickhouse
- Clickhouse.cloud
Env Variables for self hosted click house
CLICKHOUSE_HOST = "localhost"
CLICKHOUSE_PORT = "8123"
CLICKHOUSE_USERNAME = "admin"
CLICKHOUSE_PASSWORD = "admin"
Env Variables for cloud click house
CLICKHOUSE_HOST = "hjs1z7j37j.us-east1.gcp.clickhouse.cloud"
CLICKHOUSE_PORT = "8443"
CLICKHOUSE_USERNAME = "default"
CLICKHOUSE_PASSWORD = "M~PimRs~c3Z6b"
Step 3: Start the proxy, make a test request
Start proxy
litellm --config config.yaml --debug
Test Request
litellm --test
Logging Proxy Input/Output - s3 Buckets
We will use the --config to set
litellm.success_callback = ["s3"]
This will log all successfull LLM calls to s3 Bucket
Step 1 Set AWS Credentials in .env
AWS_ACCESS_KEY_ID = ""
AWS_SECRET_ACCESS_KEY = ""
AWS_REGION_NAME = ""
Step 2: Create a config.yaml file and set litellm_settings: success_callback
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
success_callback: ["s3"]
s3_callback_params:
s3_bucket_name: logs-bucket-litellm # AWS Bucket Name for S3
s3_region_name: us-west-2 # AWS Region Name for S3
s3_aws_access_key_id: os.environ/AWS_ACCESS_KEY_ID # us os.environ/<variable name> to pass environment variables. This is AWS Access Key ID for S3
s3_aws_secret_access_key: os.environ/AWS_SECRET_ACCESS_KEY # AWS Secret Access Key for S3
s3_endpoint_url: https://s3.amazonaws.com # [OPTIONAL] S3 endpoint URL, if you want to use Backblaze/cloudflare s3 buckets
Step 3: Start the proxy, make a test request
Start proxy
litellm --config config.yaml --debug
Test Request
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "Azure OpenAI GPT-4 East",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
]
}'
Your logs should be available on the specified s3 Bucket
Team-based Logging
Set success callbacks (e.g. langfuse), for a specific team-id.
litellm_settings:
default_team_settings:
- team_id: my-secret-project
success_callback: ["langfuse"]
langfuse_public_key: os.environ/LANGFUSE_PUB_KEY_2
langfuse_secret: os.environ/LANGFUSE_PRIVATE_KEY_2
- team_id: ishaans-secret-project
success_callback: ["langfuse"]
langfuse_public_key: os.environ/LANGFUSE_PUB_KEY_3
langfuse_secret: os.environ/LANGFUSE_SECRET_3
Now, when you generate keys for this team-id
curl -X POST 'http://0.0.0.0:4000/key/generate' \
-H 'Authorization: Bearer sk-1234' \
-H 'Content-Type: application/json' \
-D '{"team_id": "ishaans-secret-project"}'
All requests made with these keys will log data to their team-specific logging.
Logging Proxy Input/Output - DynamoDB
We will use the --config to set
litellm.success_callback = ["dynamodb"]litellm.dynamodb_table_name = "your-table-name"
This will log all successfull LLM calls to DynamoDB
Step 1 Set AWS Credentials in .env
AWS_ACCESS_KEY_ID = ""
AWS_SECRET_ACCESS_KEY = ""
AWS_REGION_NAME = ""
Step 2: Create a config.yaml file and set litellm_settings: success_callback
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
success_callback: ["dynamodb"]
dynamodb_table_name: your-table-name
Step 3: Start the proxy, make a test request
Start proxy
litellm --config config.yaml --debug
Test Request
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "Azure OpenAI GPT-4 East",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
]
}'
Your logs should be available on DynamoDB
Data Logged to DynamoDB /chat/completions
{
"id": {
"S": "chatcmpl-8W15J4480a3fAQ1yQaMgtsKJAicen"
},
"call_type": {
"S": "acompletion"
},
"endTime": {
"S": "2023-12-15 17:25:58.424118"
},
"messages": {
"S": "[{'role': 'user', 'content': 'This is a test'}]"
},
"metadata": {
"S": "{}"
},
"model": {
"S": "gpt-3.5-turbo"
},
"modelParameters": {
"S": "{'temperature': 0.7, 'max_tokens': 100, 'user': 'ishaan-2'}"
},
"response": {
"S": "ModelResponse(id='chatcmpl-8W15J4480a3fAQ1yQaMgtsKJAicen', choices=[Choices(finish_reason='stop', index=0, message=Message(content='Great! What can I assist you with?', role='assistant'))], created=1702641357, model='gpt-3.5-turbo-0613', object='chat.completion', system_fingerprint=None, usage=Usage(completion_tokens=9, prompt_tokens=11, total_tokens=20))"
},
"startTime": {
"S": "2023-12-15 17:25:56.047035"
},
"usage": {
"S": "Usage(completion_tokens=9, prompt_tokens=11, total_tokens=20)"
},
"user": {
"S": "ishaan-2"
}
}
Data logged to DynamoDB /embeddings
{
"id": {
"S": "4dec8d4d-4817-472d-9fc6-c7a6153eb2ca"
},
"call_type": {
"S": "aembedding"
},
"endTime": {
"S": "2023-12-15 17:25:59.890261"
},
"messages": {
"S": "['hi']"
},
"metadata": {
"S": "{}"
},
"model": {
"S": "text-embedding-ada-002"
},
"modelParameters": {
"S": "{'user': 'ishaan-2'}"
},
"response": {
"S": "EmbeddingResponse(model='text-embedding-ada-002-v2', data=[{'embedding': [-0.03503197431564331, -0.020601635798811913, -0.015375726856291294,
}
}
Logging Proxy Input/Output - Sentry
If api calls fail (llm/database) you can log those to Sentry:
Step 1 Install Sentry
pip install --upgrade sentry-sdk
Step 2: Save your Sentry_DSN and add litellm_settings: failure_callback
export SENTRY_DSN="your-sentry-dsn"
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
# other settings
failure_callback: ["sentry"]
general_settings:
database_url: "my-bad-url" # set a fake url to trigger a sentry exception
Step 3: Start the proxy, make a test request
Start proxy
litellm --config config.yaml --debug
Test Request
litellm --test
Logging Proxy Input/Output Traceloop (OpenTelemetry)
Traceloop allows you to log LLM Input/Output in the OpenTelemetry format
We will use the --config to set litellm.success_callback = ["traceloop"] this will log all successfull LLM calls to traceloop
Step 1 Install traceloop-sdk and set Traceloop API key
pip install traceloop-sdk -U
Traceloop outputs standard OpenTelemetry data that can be connected to your observability stack. Send standard OpenTelemetry from LiteLLM Proxy to Traceloop, Dynatrace, Datadog , New Relic, Honeycomb, Grafana Tempo, Splunk, OpenTelemetry Collector
Step 2: Create a config.yaml file and set litellm_settings: success_callback
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
success_callback: ["traceloop"]
Step 3: Start the proxy, make a test request
Start proxy
litellm --config config.yaml --debug
Test Request
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "what llm are you"
}
]
}'
Logging Proxy Input/Output Athina
Athina allows you to log LLM Input/Output for monitoring, analytics, and observability.
We will use the --config to set litellm.success_callback = ["athina"] this will log all successfull LLM calls to athina
Step 1 Set Athina API key
ATHINA_API_KEY = "your-athina-api-key"
Step 2: Create a config.yaml file and set litellm_settings: success_callback
model_list:
- model_name: gpt-3.5-turbo
litellm_params:
model: gpt-3.5-turbo
litellm_settings:
success_callback: ["athina"]
Step 3: Start the proxy, make a test request
Start proxy
litellm --config config.yaml --debug
Test Request
curl --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Content-Type: application/json' \
--data ' {
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": "which llm are you"
}
]
}'